Outline
- The Bellman Equations ( 벨먼 방정식)
- Policy Extraction (정책 추출)
- Policy Evaluation(정책 평가)
- Policy Iteration(정책 반복)
I. 벨먼 방정식
벨먼 방정식은 동적 프로그래밍과 강화 학습에서 중요한 개념으로 사용됩니다.
최적의 가치 함수를 구하는데 활용되며, 현재 상태의 가치를 최적으로 갱신하는 방법을 제시합니다.
II. 정책 추출
정책 추출은 주어진 환경에서 최적의 행동 정책을 찾아내는 과정입니다.
벨먼 방정식을 활용하여 최적의 정책을 발견하고 추출하는데 사용됩니다.
III. 정책 평가
정책 평가는 주어진 정책이 얼마나 좋은지를 측정하는 과정입니다.
주어진 정책에 따라 상태 가치 함수를 평가하여 정책의 성능을 추정합니다.
IV. 정책 반복
정책 반복은 정책 추출과 정책 평가를 번갈아가며 수행하여 최적의 정책을 찾는 방법입니다.
초기 정책에서 시작하여 벨먼 방정식을 통해 정책을 개선하고, 이를 반복함으로써 최적의 정책을 찾아냅니다.
Bellman Equations
최적화하는 방법(how to be optimal)
"벨먼 방정식"은 동적 프로그래밍과 강화 학습에서 사용되는 중요한 개념 중 하나입니다.
- 올바른 첫 번째 행동을 취하라 (Take correct first action): 이는 문제나 환경에 대한 초기 행동으로, 최적의 결과를 얻기 위해 처음에 올바른 행동을 선택해야 한다는 의미입니다. 초기 단계에서의 올바른 행동 선택은 후속 단계에서 더 나은 결과를 이끌어낼 수 있습니다.
- 계속해서 최적이 되어라 (Keep being optimal): 벨먼 방정식은 최적의 상태 가치 함수를 찾기 위해 현재 상태의 가치를 최적으로 갱신하는 개념을 포함하고 있습니다. 이는 현재의 최적 상태를 유지하면서 미래의 최적 상태를 찾아가는 과정을 반복해야 한다는 아이디어를 나타냅니다. 즉, 최적의 상태를 유지하면서 시스템이나 에이전트는 계속해서 미래에 최적의 행동을 선택하도록 발전해나가야 합니다.
- expectimax 재귀를 통한 "최적 유틸리티"의 정의는 최적 유틸리티 값들 간의 간단한 one-step 전망(lookahead) 관계를 제공한다.




- 이러한 벨만 방정식들은 우리가 반복적으로 사용할 수 있는 방식으로 최적의 값을 설명합니다.
"최적 유틸리티"의 정의: 여기서 최적 유틸리티는 expectimax 재귀를 통해 정의되며, 이는 최적 유틸리티 값들 간의 한 단계 전망 관계를 제공합니다. Expectimax는 기댓값과 최대값을 함께 고려하여 최적의 행동을 선택하는 알고리즘입니다.
벨먼 방정식의 특성화: 벨먼 방정식은 최적 값을 나타내는데 사용되며, 이 방정식은 최적 가치들 간의 관계를 나타냅니다. 이것은 동적 프로그래밍과 강화 학습에서 최적의 상태 가치나 행동 가치를 찾는 데 사용되는 핵심적인 도구 중 하나입니다. 최적의 가치를 찾는 과정에서 벨먼 방정식은 현재 상태의 최적 가치를 찾고, 이를 기반으로 미래 상태의 최적 가치를 예측하는데 사용됩니다. 이를 반복함으로써 최종적으로 전체 시스템이나 에이전트의 최적 정책을 찾을 수 있습니다.
Value Iteration
- 벨먼 방정식은 최적 값들을 특성화(characterize)합니다. :

- 가치 반복은 이들을 계산합니다. :

- 가치 반복은 그저 고정점 해법 방법(fixed point solution)일 뿐입니다. :
... 하지만 𝑉_𝑘 벡터들은 시간 제한된 가치로 해석할 수도 있습니다.

- 벨먼 방정식은 최적 값들을 특성화합니다: 벨먼 방정식은 동적 프로그래밍과 강화 학습에서 사용되는 중요한 수학적 방정식으로, 최적 가치를 나타냅니다. 즉, 현재 상태에서 최적 가치를 찾고, 이를 기반으로 미래 상태의 최적 가치를 예측합니다.
- 가치 반복은 이들을 계산합니다: 가치 반복은 벨먼 방정식을 활용하여 최적 가치를 계산하는 알고리즘입니다. 이는 초기 가치를 설정하고 반복적으로 벨먼 업데이트를 수행하여 최적 가치에 수렴합니다.
- 가치 반복은 그저 고정점 해법 방법일 뿐입니다: 가치 반복은 벨먼 방정식의 해를 찾는 방법 중 하나로, 반복적인 업데이트를 통해 최적 가치에 수렴하는 고정점을 찾는 방법입니다.
- 𝑉_𝑘 벡터들은 시간 제한된 가치로 해석할 수도 있습니다: 이 문장은 가치 반복의 반복 단계를 나타내는 𝑉_𝑘 벡터들이 시간에 따라 변화하는 값으로 해석될 수 있다는 것을 언급합니다. 이는 가치 반복이 시간에 따라 최적 가치를 발견하는 과정으로 해석될 수 있음을 나타냅니다.
Policy Methods( 정책 메소드)
정책 메소드는 강화 학습에서 사용되는 전략 중 하나로, 환경과 상호작용하며 최적의 행동 정책을 찾는 방법론입니다.
정책 메소드는 강화 학습에서 에이전트가 환경과 상호작용하면서 학습하는 방법 중 하나입니다. 이 방법에서는 에이전트가 각 상태에서 어떤 행동을 선택해야 하는지를 나타내는 정책(policy)을 직접 학습하려고 합니다. 정책은 주어진 상태에서 어떤 행동을 취할지를 결정하는 규칙이며, 목표는 최적의 정책을 찾는 것입니다.
정책 메소드는 주로 정책 그라디언트 방법 등의 기법을 사용하여 최적의 정책을 찾는 방향으로 학습을 진행합니다. 이는 상태 공간에서 직접 정책을 탐색하고 향상시키는 것에 중점을 둔 방법으로, 보상을 최대화하는 효율적인 행동을 찾기 위해 정책을 조정하고 향상시킵니다.
Policy Extraction(정책 추출)
정책 추출은 강화 학습에서 학습된 정책을 해석하고 추출하는 과정을 나타냅니다. 강화 학습에서 정책(policy)은 에이전트가 특정 상태에서 어떤 행동을 선택해야 하는지를 결정하는 규칙이며, 학습 과정 동안 이 정책이 최적의 행동을 찾도록 개선됩니다.
정책 추출은 학습된 정책을 분석하여 그 결과를 이해하고, 이를 특정 문제나 환경에 적용하거나 해석하는 데 사용됩니다. 이 과정에서 추출된 정책은 문제 해결이나 실제 시나리오에서 에이전트의 의사 결정에 적용될 수 있습니다.
정책 추출은 종종 학습된 정책을 명확하고 해석 가능한 형태로 변환하거나 시각화하는 과정을 포함할 수 있습니다. 이는 강화 학습의 결과를 해석하고 효과적으로 활용하기 위해 중요한 단계 중 하나입니다.
Computing Actions from Values

- 최적의 값 V*(s)를 갖는다고 가정해 봅시다.
- 어떻게 행동해야 할까요?
- 명확하지 않습니다!
- 우리는 미니-기대값(Max)을 계산해야 합니다 (한 단계에 대한)

- 이것은 정책 추출이라고 불리며, 값에 의해 암시된 정책을 가져오는 과정입니다.
위 문장은 최적의 상태 가치 V*(s)가 주어진 상황에서 어떻게 행동해야 하는지에 대한 고민을 다루고 있습니다. 이를 통해 정책 추출이라는 개념이 소개됩니다.
- 최적의 값 V*(s)를 갖는다고 가정해 봅시다: 학습된 시스템이나 에이전트가 각 상태에 대해 최적의 가치를 학습했다고 가정합니다.
- 어떻게 행동해야 할까요? - 명확하지 않습니다!: 최적의 값이 주어졌을 때, 실제로 어떤 행동을 취해야 하는지는 명확하지 않다고 설명합니다.
- 미니-기대값(Max)을 계산해야 합니다 (한 단계에 대한): 한 단계를 내다봄으로써 미래 예상 가치를 고려하여 행동을 결정해야 한다는 개념입니다.
- 이것은 정책 추출이라고 불리며, 값에 의해 암시된 정책을 가져오는 과정입니다: 최적의 값이 암시하는 정책을 추출하기 위해 미니-기대값 계산을 통해 행동을 선택하는 과정을 정책 추출이라고 부릅니다. 이는 최적의 가치에 기반하여 최적의 행동을 결정하는 과정을 의미합니다.
Computing Actions from Q-Values

- 최적의 Q-값이 있다고 가정해 봅시다.
- 어떻게 행동해야 할까요?
- 결정하기가 완전히 간단합니다!

- 중요한 교훈: 행동은 값(value)보다 Q-값(q-value)에서 선택하기가 더 쉽습니다!
위 문장은 최적의 Q-값이 주어진 상황에서 어떻게 행동해야 하는지에 대한 고민을 다루고 있습니다.
- 최적의 Q-값이 있다고 가정해 봅시다: Q-값은 특정 상태에서 특정 행동을 취할 때의 기대값을 나타내는 값으로, 최적의 경우에 해당하는 Q-값이 주어졌다고 가정합니다.
- 어떻게 행동해야 할까요? - 결정하기가 완전히 간단합니다!: 최적의 Q-값이 주어진 상황에서 어떤 행동을 선택해야 하는지 결정하는 것은 매우 간단하다고 설명합니다.
- 중요한 교훈: 행동은 값보다 Q-값에서 선택하기가 더 쉽습니다!: 행동을 선택하는 것은 상태 가치 값보다 Q-값에서 선택하는 것이 더 간단하다는 중요한 교훈을 언급합니다. Q-값은 특정 행동에 대한 가치를 더 직접적으로 제공하므로, 최적의 행동을 선택하는 것이 상대적으로 쉽다는 것을 강조합니다.
Problems with Value Iteration
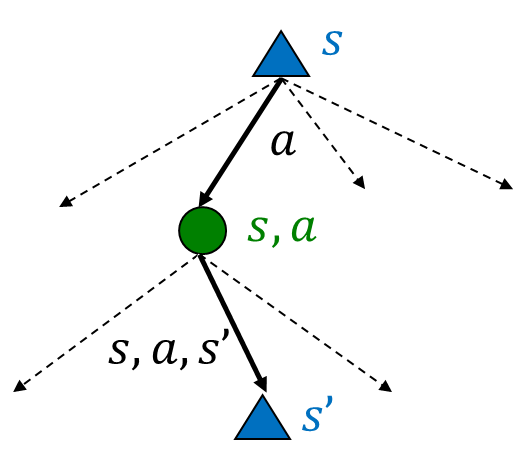
- 가치 반복은 벨만 업데이트를 반복합니다:

- 문제 1: 느림 - 각 반복마다 𝑂(𝑆^2 𝐴)의 시간 복잡도
- 문제 2: 각 상태에서의 "최대값(max)"이 드물게 변경됨
- 문제 3: 정책이 종종 값들보다 훨씬 빨리 수렴함
위 문장은 가치 반복 알고리즘의 한계와 문제점들을 다루고 있습니다.
- 가치 반복은 벨만 업데이트를 반복합니다: 가치 반복은 벨만 방정식에 기반하여 최적 가치를 반복적으로 업데이트하는 알고리즘입니다.
- 문제 1: 느림 - 각 반복마다 𝑂(𝑆^2 𝐴)의 시간 복잡도: 가치 반복의 주요 문제 중 하나는 각 반복이 매우 느리다는 것입니다. 각 반복에서의 시간 복잡도가 상태 수(𝑆)의 제곱과 행동 수(𝐴)에 비례한다는 것을 의미합니다.
- 문제 2: 각 상태에서의 "최대값(max)"이 드물게 변경됨: 각 상태에서 최대값이 자주 변경되지 않는다는 것은 가치 반복이 수렴에 필요 이상으로 계산을 반복하고 있다는 것을 의미할 수 있습니다.
- 문제 3: 정책이 종종 값들보다 훨씬 빨리 수렴함: 가치 반복에서 정책이 가치보다 빠르게 수렴하는 문제가 발생할 수 있습니다. 이는 최적 정책을 찾는 데 불필요한 계산이 이루어질 수 있음을 나타냅니다.

Policy Iteration(정책 반복)
정책 반복은 강화 학습에서 사용되는 알고리즘 중 하나로, 정책을 반복적으로 평가하고 개선하여 최적의 정책을 찾는 과정입니다.
정책 반복은 가치 반복과는 다르게 정책을 직접 평가하고 개선하는 방식으로 최적의 정책을 찾습니다. 아래는 정책 반복의 주요 단계입니다:
- 초기 정책 설정: 먼저 초기에 어떤 행동을 선택할지를 정하는 초기 정책을 설정합니다.
- 정책 평가: 설정된 정책을 기반으로 상태 가치 함수를 평가합니다. 각 상태의 가치는 해당 정책을 따랐을 때 얻을 수 있는 기대 반환값으로 계산됩니다.
- 정책 개선: 평가된 상태 가치를 기반으로 현재 정책을 개선합니다. 각 상태에서 높은 가치를 갖는 행동을 선택하도록 정책을 조정합니다.
- 수렴 검사: 정책이 수렴했는지를 확인하고, 만약 수렴하지 않았다면 다시 2단계부터 반복합니다.
정책 반복은 정책이 최적에 수렴할 때까지 이러한 단계를 반복하며, 가치 함수를 명시적으로 추정하지 않고도 최적 정책을 찾는 효과적인 방법 중 하나입니다.
Policy Evaluation(정책 평가)
정책 평가는 강화 학습에서 사용되는 과정으로, 주어진 정책에 따라 각 상태의 가치를 추정하는 과정입니다.
정책 평가는 특정 정책이 주어졌을 때, 각 상태의 가치를 예측하는 과정입니다. 정책 평가는 강화 학습의 반복적인 프로세스 중 하나로, 아래와 같은 단계로 이루어집니다:
- 초기 가치 설정: 먼저 상태 가치 함수의 초기값을 설정합니다. 이는 초기에는 임의의 값이 될 수 있습니다.
- 상태 가치 업데이트: 현재의 상태 가치를 기반으로 각 상태의 새로운 가치를 업데이트합니다. 이때 벨만 방정식을 활용하여 현재 정책에 따른 가치를 예측합니다.
- 수렴 검사: 새로 업데이트된 가치 함수가 수렴했는지를 확인합니다. 만약 수렴하지 않았다면, 2단계로 돌아가 반복합니다.
- 최종 가치 함수 반환: 수렴된 가치 함수를 최종적으로 반환합니다.
정책 평가는 정책이나 환경이 변하지 않는 한 계속 반복되며, 최종적으로는 주어진 정책에 대한 각 상태의 최적 가치를 찾게 됩니다. 이는 정책 개선과 같은 다른 강화 학습 알고리즘에서 중요한 단계 중 하나입니다.
정책 메소드/ 정책 평가 / 정책 반복 ... 등은 한번 검색해서 알아보자
Fixed Policies
- 최적의 행동 수행

- 정책 𝜋가 지시하는 대로 행동 수행

- 기대값 트리는 최적 값을 계산하기 위해 모든 행동을 최대화함
- 만약 우리가 어떤 정책 𝜋(𝑠)를 고정한다면, 트리는 각 상태에 대해 하나의 행동만을 갖게 될 것이다.
- ... 그러나 트리의 값은 우리가 어떤 정책을 고정했느냐에 따라 달라질 것이다.
- 최적의 행동 수행: 최적 정책을 따를 때는 항상 최적의 행동을 수행합니다.
- 정책 𝜋가 지시하는 대로 행동 수행: 어떤 특정 정책 𝜋에 따라서 그 정책이 권장하는 행동을 따라 수행합니다.
- 기대값 트리는 최적 값을 계산하기 위해 모든 행동을 최대화함: Expectimax 트리는 모든 가능한 행동에 대해 기대값을 계산하며, 이를 통해 최적 가치를 결정합니다.
- 만약 우리가 어떤 정책 𝜋(𝑠)를 고정한다면, 트리는 각 상태에 대해 하나의 행동만을 갖게 될 것이다: 만약 우리가 어떤 정책을 고정하면, 행동은 상태마다 하나씩만 선택하게 됩니다.
- ... 그러나 트리의 값은 우리가 어떤 정책을 고정했느냐에 따라 달라질 것이다: 하지만 트리의 값은 그 트리를 만들 때 사용한 정책에 따라 달라질 것입니다. 다양한 정책을 시도하면 서로 다른 결과를 얻을 수 있습니다.