[인공지능] Reinforcement Learning I - 1
Outline
Double Bandits (이중 밴딧)
Initially Unknown MDPs (초기에 알려지지 않은 MDPs)
Model-Based Learning (모델 기반 학습)
Model-Free Learning (모델 없는 학습)
- Direct Estimation (직접 추정)
- Temporal Difference Learning (시간차 학습)
- Q-Learning
1. Double Bandits (이중 밴딧)
- 개요: Double 밴딧은 강화 학습에서 사용되는 전략 중 하나로, 두 가지 다른 리워드 또는 정보 소스를 고려하는 알고리즘을 나타냅니다. 이는 두 가지 다른 리워드 시스템 간의 균형을 맞추거나 최적의 전략을 찾는 데 도움이 될 수 있습니다.
2. Initially Unknown MDPs (초기에 알려지지 않은 MDPs)
- 개요: 초기에 Markov Decision Processes (MDPs)가 알려지지 않은 상태에서 강화 학습 문제를 다루는 것을 의미합니다. 에이전트는 환경의 구조나 보상 함수를 사전에 알지 못하며, 학습 과정을 통해 이러한 정보를 습득하려고 합니다.
3. Model-Based Learning (모델 기반 학습)
- 개요: 모델 기반 학습은 환경의 모델을 명시적으로 구축하고 사용하여 최적의 행동을 선택하는 강화 학습 방법 중 하나입니다. 환경 모델을 사용하여 에이전트는 미래 상태 및 보상을 예측하고 이를 기반으로 행동을 결정합니다.
4. Model-Free Learning (모델 없는 학습)
- 개요: 모델 없는 학습은 환경의 모델을 명시적으로 구축하지 않고, 주어진 상태에서 직접적으로 행동 가치를 학습하여 최적의 정책을 찾는 방법입니다.
- a. Direct Estimation (직접 추정): 에이전트는 행동 가치를 직접 추정하여 학습하고, 이를 기반으로 최적의 행동을 선택합니다.
- b. Temporal Difference Learning (시간차 학습): 현재 상태의 가치를 이용하여 이전 상태의 가치를 업데이트하면서 학습합니다.
- c. Q-Learning: Q-러닝은 특정 상태에서 가능한 각 행동에 대한 가치를 추정하고, 최적의 정책을 찾기 위해 이를 반복적으로 업데이트합니다.
이러한 개념들은 강화 학습 분야에서 다양한 문제 해결을 위한 다양한 전략과 방법론을 제공합니다.
Double Bandits

- 행동 (Actions): 파란색 (Blue), 빨간색 (Red)
- 상태 (States): 이기기 (Win), 지기 (Lose)
- 할인 없음 (No discount): 미래 보상에 대한 할인율이 없습니다.
- 100 타임 스텝 (100 time steps): 에이전트가 행동을 선택하고 환경에서 반응하는 시간 단계는 총 100회입니다.
- 동일한 가치 (Both states have the same value): 이기기와 지기 상태는 동일한 가치를 가지고 있습니다.
이 문제에서 이중 밴딧은 두 가지 다른 행동 (파란색 또는 빨간색 선택)과 두 가지 다른 상태 (이기기 또는 지기)로 정의됩니다. 할인율이 없으므로 미래 보상이 현재와 동일한 가치를 가집니다.
에이전트는 각 타임 스텝에서 파란색 또는 빨간색 중 하나의 행동을 선택하고, 그 결과로 이기기 또는 지기 상태로 이동합니다. 상태에 따라 보상이 주어지며, 에이전트는 이러한 보상을 최대화하도록 학습합니다.
두 상태가 동일한 가치를 가지고 있기 때문에 에이전트는 두 상태 모두에서 가능한 최적의 행동을 찾는 전략을 개발해야 합니다. 할인율이 없으므로 에이전트는 각 타임 스텝에서 즉시 최대 보상을 얻는 방향으로 학습을 진행할 것입니다.
Offline Planning

- MDP 해결은 오프라인 계획이다:
- 계산을 통해 모든 양을 결정 (You determine all quantities through computation)
- MDP의 세부 사항을 알아야 함 (You need to know the details of the MDP)
- 실제로 게임을 플레이하지는 않음 (You do not actually play the game)
- 설명: 오프라인 계획은 강화 학습에서 사용되는 Markov Decision Processes (MDPs)를 해결하는 접근 방식 중 하나입니다. 이는 모든 계산을 통해 모든 양을 결정하는 방식으로 이루어집니다.
- MDP 해결에서는 환경의 모든 세부 사항과 관련된 값을 계산하여 결정합니다. 에이전트가 행동을 선택하고 각 상태에서 기대되는 가치 등을 사전에 계획합니다.
- MDP를 해결하려면 해당 환경의 세부 사항을 사전에 알아야 합니다. 즉, 상태, 행동, 보상 및 전이 확률과 같은 MDP의 구성 요소에 대한 정보가 필요합니다.
- 오프라인 계획은 게임이나 환경을 직접 탐험하거나 상호 작용하지 않습니다. 대신, 사전에 수집된 MDP의 세부 사항을 기반으로 계산을 수행하여 최적의 정책이나 가치 함수를 결정합니다. 이를 통해 에이전트는 효율적으로 학습할 수 있습니다.
Let's Play!

Online Planning
규칙이 바뀌었다! 빨간색의 승리 확률이 달라진다.

온라인 계획은 환경이나 규칙이 변하는 동안 실시간으로 계획을 조정하고 새로운 정보를 토대로 의사 결정을 내리는 강화 학습의 전략을 나타냅니다.
Let's play!

What Just Happened?
- 그것은 계획이 아니었고, 학습이었습니다!
- 구체적으로는 강화 학습
- MDP가 있었지만, 단순한 계산으로는 해결할 수 없었습니다
- 실제로 행동해야만 그것을 이해할 수 있었습니다."
- "그것은 계획이 아니었고, 학습이었습니다!"라는 부분은 어떤 일이 계획된 것이 아니라 우연하게 발생한 것이 아니라 학습을 통해 이뤄진 것이라고 설명하고 있습니다.
- "- 구체적으로는 강화 학습"은 어떤 종류의 학습이 이루어졌는지를 설명하고 있습니다. 여기서는 "강화 학습"이라는 특정한 학습 방법이 사용되었다고 언급하고 있습니다.
- "- MDP가 있었지만, 단순한 계산으로는 해결할 수 없었습니다"는 이 학습이 Markov Decision Process (MDP)라는 수학적 모델에 기반하고 있었지만, 이를 단순한 계산만으로 해결할 수 없었다는 것을 나타냅니다.
- "- 실제로 행동해야만 그것을 이해할 수 있었습니다."는 문제를 해결하려면 단순한 계산뿐만 아니라 실제로 행동을 취해야 했다는 것을 강조하고 있습니다. 이는 강화 학습에서는 에이전트가 환경과 상호작용하며 경험을 통해 학습하는 특징을 나타냅니다.
Reinforcement learning
- 초기에 MDP가 알려지지 않았을 때, 많은 것들이 변합니다!
- 탐험: 정보를 얻기 위해 알려지지 않은 행동을 시도해야 합니다
- 활용: 최종적으로는 알고 있는 것을 사용해야 합니다
- 후회: 초기에는 불가피하게 '실수'를 하고 보상을 잃게 됩니다
- 샘플링: 좋은 추정을 얻기 위해 많은 시도가 필요할 수 있습니다
- 일반화: 한 상태에서 학습한 내용이 다른 상태에도 적용될 수 있습니다"
이 문장은 강화 학습에 관련된 여러 개념들을 다루고 있습니다.
- "초기에 MDP가 알려지지 않았을 때, 많은 것들이 변합니다!"는 Markov Decision Process (MDP)가 처음에는 알려지지 않은 상태에서 시작되는 경우를 언급하고 있습니다.
- "탐험: 정보를 얻기 위해 알려지지 않은 행동을 시도해야 합니다"는 에이전트가 새로운 행동을 시도하고 환경에서 정보를 얻으려는 과정을 나타냅니다. 즉, 에이전트는 처음에는 환경을 탐험하면서 학습합니다.
- "활용: 최종적으로는 알고 있는 것을 사용해야 합니다"는 탐험이 끝나면 에이전트가 알고 있는 지식을 활용하여 최적의 행동을 선택해야 한다는 것을 나타냅니다.
- "후회: 초기에는 불가피하게 '실수'를 하고 보상을 잃게 됩니다"는 초기에는 에이전트가 환경을 더 잘 이해하지 못해 '실수'를 하고 이로 인해 보상을 잃을 수 있다는 것을 의미합니다.
- "샘플링: 좋은 추정을 얻기 위해 많은 시도가 필요할 수 있습니다"는 환경을 이해하고 최적의 행동을 결정하기 위해서는 여러 번의 시도와 경험이 필요하다는 것을 강조합니다.
- "일반화: 한 상태에서 학습한 내용이 다른 상태에도 적용될 수 있습니다"는 에이전트가 특정 상태에서 얻은 지식이 비슷한 다른 상태에서도 유용하게 활용될 수 있다는 것을 나타냅니다.
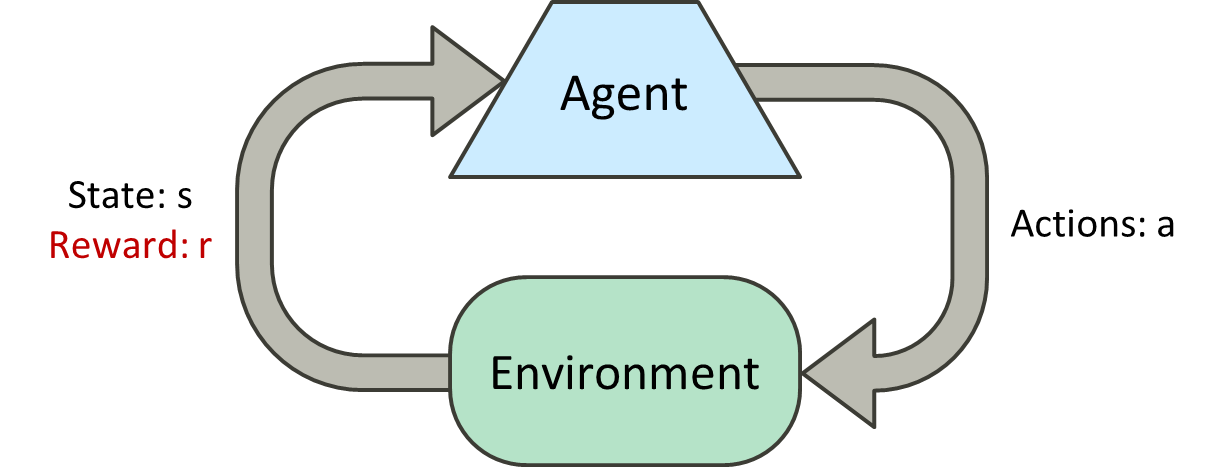
- 관측된 전이(transitions) 샘플을 기반으로 예상 보상을 최대화하는 방법을 학습합니다
- 모든 생명체가 직면하는 기본적인 문제와 비슷함
이 부분은 강화 학습의 기본 아이디어에 대해 설명하고 있습니다.
- "관측된 전이 샘플을 기반으로 예상 보상을 최대화하는 방법을 학습합니다":
- 강화 학습은 에이전트가 환경과 상호작용하면서 어떤 행동을 취할지 학습하는 것입니다.
- 학습 과정에서 에이전트는 환경으로부터 관측된 상태(state)와 보상(reward)에 대한 정보를 얻습니다.
- 이 정보를 기반으로 에이전트는 어떤 행동을 취할지 결정하고, 이로 인해 새로운 상태로 전이됩니다(transitions).
- "모든 생명체가 직면하는 기본적인 문제와 비슷함":
- 이 부분은 강화 학습이 추상적으로 생물체들이 일상적으로 직면하는 문제와 유사하다는 점을 강조하고 있습니다.
- 모든 생명체는 자신의 행동에 대한 피드백을 받으며, 이를 통해 환경과 상호작용하면서 생존과 번식과 같은 목표를 달성하려고 노력합니다.
- 강화 학습은 이러한 기본적인 원리를 기반으로 하고 있으며, 에이전트가 보상을 최대화하며 목표를 달성하도록 학습됩니다.
Example : Learning to walk
- 행동을 직접 실행하면서 초기에는 로봇이 걷는게 이상했지만 피드백을 계속해서 적용받으면서 final에는 우수한 퍼포먼스가 나옴
Example: Breakout (DeepMind) , AlphaGo
- 딥마인드에서도 딥 Q러닝을 사용했고 처음에는 어떤행동을 하는건지 모르면서 10분간 학습하다가 120분 후에는 전문가처럼 play했음. 240분 후에는 벽돌깨기 게임에서 어떻게하면 효율적으로(사기기술 쓰듯이) 게임 깰 수 있는지 인간보다 능지가 뛰어나게 게임함
The Crawler!
- Crawler 로봇은 포크레인 처럼 생긴 로봇이 지게의 원리를 이용해 앞으로 이동하는 행동을 구현하는 것같은데 처음에는 조금씩 잘 못움직였다. 근데 입실론을 줄이니까 ( 아마 입실론의 확률로 다른 돌발행동을 하는것을 말하는 듯) 예측대로 움직이고 일관적인 행동을 보여서 앞으로 잘 갔다.
Reinforcement Learning
여전히 마르코프 결정 과정(MDP)을 가정합니다:
- 상태의 집합 𝑠∈𝑆
- 각 상태별 행동의 집합 𝐴(𝑠)
- 전이 모델 𝑇(𝑠,𝑎,𝑠’)
- 보상 함수 𝑅(𝑠,𝑎,𝑠’)
여전히 정책 π(𝑠)을 찾고 있다.
새로운 변화 : 전이 모델 𝑇 또는 보상 함수 𝑅을 모른다
- 즉, 어떤 상태가 좋은지 또는 행동들이 무엇을 하는지 알 수 없습니다.
- 새로운 상태와 행동을 탐색해야 합니다 -- 이전에 Pacman이 가보지 않았던 곳으로 대담하게 나아가야 합니다.
이 텍스트는 강화 학습에 대한 설명입니다. 강화 학습은 마르코프 결정 과정(MDP)을 기반으로 하며, 여기에는 여러 주요 요소들이 포함됩니다:
- 상태 집합 𝑆: 가능한 모든 상태들의 집합입니다. 여기서 상태란 시스템이나 환경의 특정 조건을 의미합니다.
- 행동 집합 𝐴(𝑠): 각 상태에서 가능한 행동들의 집합입니다. 이 행동들은 상태를 다른 상태로 변화시킬 수 있습니다.
- 전이 모델 𝑇(𝑠,𝑎,𝑠’): 한 상태에서 특정 행동을 취했을 때 다른 상태로 이동할 확률을 나타냅니다. 이는 상태 𝑠에서 행동 𝑎를 취했을 때 상태 𝑠'로 이동하는 것을 모델링합니다.
- 보상 함수 𝑅(𝑠,𝑎,𝑠’): 상태와 행동의 쌍이 주어졌을 때 받을 수 있는 보상을 정의합니다. 이는 특정 행동이 얼마나 좋은 결과를 가져오는지를 평가하는 데 사용됩니다.
강화 학습에서는 정책 π(𝑠)을 찾는 것이 목표입니다. 정책은 특정 상태에서 어떤 행동을 취할지를 결정하는 규칙입니다.
하지만 이 경우의 새로운 도전은 전이 모델 𝑇이나 보상 함수 𝑅이 알려져 있지 않다는 것입니다. 즉, 어떤 상태가 좋은지, 행동이 어떤 결과를 가져오는지 미리 알 수 없습니다. 따라서 학습 과정에서 새로운 상태와 행동을 탐색해야 합니다. 이는 마치 Pacman이 전에 가보지 않은 길을 탐험하는 것과 같습니다.
Offline (MDPs) vs. Online (RL)
- 오프라인 솔루션
- 온라인 학습
이 부분은 오프라인과 온라인 학습, 특히 마르코프 결정 과정(MDPs)과 강화 학습(RL) 사이의 차이에 대해 언급하고 있습니다.
- 오프라인 솔루션 (Offline Solution): 이것은 마르코프 결정 과정(MDP)에 대한 접근 방식으로, 모델을 미리 학습시키고 이를 기반으로 최적의 결정을 내리는 방법입니다. 여기서 '오프라인'이란 학습 과정이 실시간 환경과 분리되어 이루어진다는 것을 의미합니다. 즉, 모든 필요한 데이터가 미리 수집되어 있으며, 이 데이터를 사용하여 최적의 정책을 계산합니다.
- 온라인 학습 (Online Learning): 반면, 강화 학습(RL)은 '온라인 학습' 방식을 사용합니다. 이 경우, 에이전트는 환경과 상호작용하면서 학습을 진행합니다. 즉, 에이전트는 실시간으로 환경으로부터 데이터를 수집하고, 이를 바탕으로 행동을 결정하고 정책을 조정합니다. 이 방식은 에이전트가 미지의 환경에서 효과적으로 학습하고 적응할 수 있게 해줍니다.
간단히 말해, 오프라인 솔루션은 모든 정보가 미리 주어진 상태에서 최적의 해결책을 찾는 반면, 온라인 학습은 정보가 점진적으로 얻어지는 상황에서 실시간으로 학습하고 적응하는 과정입니다.
Approaches to Reinforcement Learning
- 모델 기반: 모델을 학습하고, 해결하고, 해결책을 실행
- 경험으로부터 가치를 학습하여 결정을 내림
- 직접 평가
- 시간 차이 학습
- Q-러닝
- 정책을 직접 학습하기 (이 강좌에서는 다루지 않음)
- 모델 기반 (Model-based): 이 접근 방식에서는 먼저 환경의 모델을 학습합니다. 이 모델은 상태 간의 전이 확률과 보상을 포함합니다. 모델을 학습한 후, 이를 사용하여 최적의 정책을 찾고, 이 정책에 따라 행동을 취합니다.
- 가치 기반 학습 (Learn values from experiences): 이 방식에서는 직접적인 경험을 통해 각 상태나 행동의 가치를 학습합니다. 이는 다음과 같은 방법들을 포함합니다:
- 직접 평가 (Direct evaluation): 각 상태의 가치를 직접 평가합니다.
- 시간 차이 학습 (Temporal difference learning): 시간적 차이를 이용하여 가치 추정을 점진적으로 개선합니다.
- Q-러닝 (Q-learning): 상태-행동 쌍의 가치(즉, Q-값)를 학습하여 최적의 행동을 결정합니다.
- 정책 직접 학습 (Learn policies directly): 이 방법은 정책을 직접 학습하여 최적의 행동을 결정합니다. 이 방법은 상태의 가치를 별도로 평가하지 않고, 바로 최적의 행동을 선택하는 방법으로, 이 강좌에서는 다루지 않습니다.
요약하면, 모델 기반 접근법은 환경의 모델을 학습하고 이를 사용하여 최적의 정책을 찾는 반면, 가치 기반 학습은 경험을 통해 상태나 행동의 가치를 직접 학습합니다. 정책 직접 학습 방법은 이 과정에서 정책을 바로 학습하는데, 이는 이 강좌에서는 다루지 않는 부분입니다.