[인공지능] Reinforcement Learning II - 1
Outline
- Exploitation vs. Exploration( 착취 대 탐험)
- ε-greedy(입실론 그리디)
- Exploration function(탐험 함수)
- Generalization (일반화)
- Feature-based state representation(특징 기반 상태 표현)
- 착취 대 탐험(Exploitation vs. Exploration): 이 개념은 주로 머신러닝, 특히 강화학습에서 논의됩니다. 이미 알려진 것을 사용해 좋은 결과를 얻는 것(착취)과 새로운 것을 시도해 더 나은 전략을 발견할 가능성을 탐색하는 것(탐험) 사이의 균형에 관한 것입니다.
- ε-greedy (입실론 그리디): 이것은 강화학습에서 사용되는 전략입니다. 대부분의 경우 최고의 알려진 옵션(착취)을 선택하지만 때때로 작은 확률 ε로 무작위로 옵션을 선택합니다(탐험). 이는 현재 최고의 전략보다 더 나은 전략을 찾는 데 도움이 됩니다.
- 탐험 함수(Exploration function): 이것은 강화학습 알고리즘에서 착취와 탐험의 균형을 맞추기 위해 사용되는 방법을 말합니다. 탐험 함수는 과거 경험과 현재 학습 상태에 기반하여 새로운 옵션을 시도하는 빈도를 조정할 수 있습니다.
- 일반화(Generalization): 머신러닝에서 일반화란 모델이 훈련 데이터에서 배운 것을 새롭고 보지 못한 데이터에 적용할 수 있는 능력을 말합니다.
- 특징 기반 상태 표현(Feature-based state representation): 이것은 학습 문제에서 상태를 특징을 사용하여 나타내는 것을 말합니다. 특징은 해당 작업과 관련된 상태의 구체적인 특성이나 속성입니다. 이 접근 방식은 훈련 세트의 구체적인 상태가 아니라 이러한 특징에 초점을 맞추어 새로운 상태에 대한 학습을 일반화하는 데 도움이 됩니다.
이러한 개념들은 인공지능과 로봇공학과 같은 분야에서 다양한 상황에 학습하고 적응할 수 있는 알고리즘을 개발하는 데 있어 중요합니다.
Exploitation vs. Exploration
- 착취(Exploitation): 지금까지 배운 것을 바탕으로 최선을 다하는 것
- 탐험(Exploration): 새로운 것을 시도하는 것
- 핵심 포인트: 순수한 착취는 종종 일정한 패턴에 빠져 최적의 정책을 찾지 못한다!
- 착취(Exploitation): 이것은 알고리즘이나 에이전트가 그간의 학습을 통해 얻은 지식을 바탕으로 현재 상황에서 최적으로 판단되는 선택을 하는 것을 의미합니다. 즉, 과거의 경험에서 높은 보상을 받은 행동을 반복하는 것입니다. 이 접근법은 단기적으로는 효율적일 수 있지만, 장기적으로는 더 나은 가능성을 간과할 위험이 있습니다.
- 탐험(Exploration): 반대로 탐험은 알려지지 않은 새로운 행동이나 선택을 시도함으로써 새로운 정보를 얻거나 더 나은 전략을 발견하는 것을 의미합니다. 이는 초기에는 불확실성과 낮은 보상을 가져올 수 있지만, 장기적으로는 더 나은 해결책을 찾는 데 필수적입니다.
- 핵심 포인트: 이러한 관점에서 중요한 점은 순수하게 착취만을 하는 접근법은 종종 고정된 패턴에 빠져 새로운 또는 최적의 해결책을 발견하지 못한다는 것입니다. 강화 학습에서 이상적인 전략은 착취와 탐험 사이의 균형을 맞추는 것입니다. 탐험을 통해 새로운 정보를 수집하고, 이를 바탕으로 착취를 하는 방식으로 전략을 조절해야 합니다. 이렇게 함으로써 알고리즘은 보다 효과적으로 환경을 학습하고 최적의 정책을 발견할 수 있습니다.
Exploration method 1: 𝜖-greedy
- ε-greedy 탐험 (𝜖-greedy exploration)
- 모든 시간 단계에서 편향된 동전을 던진다.
- (작은) 확률 𝜖로 무작위로 행동한다.
- (큰) 확률 1−𝜖로 현재 정책에 따라 행동한다.
- ε-greedy 탐험의 특성 (Properties of 𝜖-greedy exploration)
- 모든 𝑠(상태), 𝑎(행동) 쌍은 무한정 시도된다.
- 많은 어리석은 행동을 한다.
- 절벽에서 여러 번 뛰어내려 그것이 아프다는 것을 확인하는 것과 같다.
- 영원히 어리석은 행동을 계속한다.
- 𝜖을 0으로 감소시킨다.
- ε-greedy 탐험 (𝜖-greedy exploration): 이 방법은 강화 학습에서 널리 사용되는 탐험 전략입니다. 매 시간 단계에서, 알고리즘은 작은 확률 𝜖로 완전히 무작위로 행동하고, 큰 확률 1−𝜖로 현재 정책(학습된 지식을 바탕으로 한 최적의 행동)을 따릅니다. 이는 학습 과정에서 탐험과 착취 사이의 균형을 맞추기 위해 설계된 방법입니다.
- ε-greedy 탐험의 특성 (Properties of 𝜖-greedy exploration):
- 무한한 시도: ε-greedy 방법은 모든 상태와 행동의 조합을 무한히 시도할 수 있게 합니다. 이는 시간이 지남에 따라 모든 가능성을 탐색할 수 있음을 의미합니다.
- 어리석은 행동: 무작위성 때문에, 이 전략은 때때로 비효율적이거나 불필요한 행동을 할 수 있습니다. 예를 들어, 알고리즘이 학습 과정에서 동일한 실수를 반복할 수 있습니다.
- 지속적인 어리석은 행동: ε-greedy 전략은 계속해서 무작위 행동을 유지합니다. 그러나, 시간이 지남에 따라 ε 값을 0으로 서서히 감소시켜 무작위 행동의 비율을 줄일 수 있습니다. 이는 처음에는 더 많은 탐험을 하고, 시간이 지날수록 더 많은 착취를 하도록 유도하는 방법입니다.
Crawler Example: Q-Learning – 𝜖-Greedy
0.8 입실론 계수로 다양한 행동을 하고 있음. 갈피를 계속 못잡고 있는 듯한 모습을 보이고 다양한 경험을 하고 있음. 입실론을 여기서 다운 시켜서 0으로 만들면? 무작위 시도를 하지않고 올바르게 앞으로 잘 가고 있는 모습이 보임.
Crawler 예제에서, Q-Learning과 ε-Greedy 전략을 결합함으로써 에이전트는 주어진 환경에서 최적의 행동을 학습하면서도 새로운 가능성을 탐색할 수 있는 균형을 찾을 수 있습니다.
Sensible Exploration: Bandits(현명한 탐험: 밴딧(Bandits))

- 다음에 어떤 한 팔 강도(One-Armed Bandit)를 시도할 것인가?
- 대부분의 사람들은 C > B > A > D 순으로 선택할 것이다.
- 기본 직관: 높은 평균이 더 좋다; 더 많은 불확실성이 더 좋다
- 기틴스(1979): 각 팔을 그 팔 자체에만 의존하는 지수로 순위를 매긴다
이 문구는 "multi-armed bandit" 문제에 대한 설명을 나타냅니다. 이는 결정 이론과 강화 학습에서 자주 다루는 문제로, 한정된 자원을 여러 선택지 중 최적의 결과를 낼 것으로 예상되는 선택지에 할당하는 문제입니다.
- 한 팔 강도(One-Armed Bandit): 여기서 '한 팔 강도'는 슬롯 머신을 의미하는 것으로 보이며, 각각의 슬롯 머신은 다른 확률과 보상 구조를 가질 수 있습니다. 에이전트(또는 사용자)는 어느 슬롯 머신이 최상의 보상을 줄지 결정해야 합니다.
- 어떤 기준으로 선택할 것인가?: 대부분의 사람들은 이미 얻은 보상의 평균이 높은 슬롯 머신을 선호할 것입니다. 그러나 불확실성이 높은 슬롯 머신도 매력적일 수 있습니다. 왜냐하면 불확실성이 높다는 것은 아직 충분히 탐험되지 않았고, 더 높은 보상을 숨기고 있을 수 있기 때문입니다.
- 기틴스 지수(Gittins Index): 기틴스는 1979년에 각각의 선택지를 순위 매기는 방법을 제안했습니다. 이 지수는 해당 선택지(여기서는 슬롯 머신의 '팔')의 과거 보상과 시도 횟수 등에 기반하여 계산됩니다. 이 지수는 보상의 기대값과 불확실성을 모두 고려하여, 장기적으로 최대의 보상을 가져올 것으로 예상되는 선택지를 선정하는 데 사용됩니다.
간단히 말해, 이는 에이전트가 각 선택지의 잠재적 가치를 평가하고 가장 높은 기대 보상을 제공할 것으로 예상되는 선택지를 선택하도록 하는 결정 프로세스입니다.
Exploration Functions

- 탐험 함수(Exploration Functions)
- 탐험 함수는 이러한 균형을 구현합니다.
- 값 추정치 𝑢와 방문 횟수 𝑛을 받아들여 낙관적인 유틸리티를 반환합니다. 예를 들어, 𝑓(𝑢,𝑛)=𝑢+𝑘/√𝑛 같은 함수를 사용합니다.
- 탐험 함수는 이러한 균형을 구현합니다.
- 정규 Q-업데이트(Regular Q-update):
- 𝑄(𝑠,𝑎)←(1−𝛼)∙𝑄(𝑠,𝑎)+𝛼∙[𝑅(𝑠,𝑎,𝑠')+𝛾 max┬(𝑎')〖𝑄(𝑠',𝑎')〗]
- 수정된 Q-업데이트(Modified Q-update):
- 𝑄(𝑠,𝑎)←(1−𝛼)⋅𝑄(𝑠,𝑎)+𝛼⋅[𝑅(𝑠,𝑎,𝑠')+𝛾 max┬(𝑎')〖𝑓(𝑄(𝑠',𝑎), 𝑛(𝑠',𝑎')〗]
- 참고: 이 방식은 "보너스"를 알려지지 않은 상태로 이어지는 상태까지 역전파하기도 합니다!
탐험 함수는 강화 학습에서 상태와 행동을 얼마나 자주 탐험했는지를 고려하여, 낙관적인 추정치를 제공하여 에이전트가 덜 방문한 상태와 행동을 탐험하도록 유도합니다.
- 값 추정치와 방문 횟수: 탐험 함수는 값 추정치(𝑢)와 방문 횟수(𝑛)를 입력으로 받습니다. 값 추정치는 특정 상태와 행동 조합의 기대 보상을 나타내며, 방문 횟수는 에이전트가 그 상태와 행동을 얼마나 자주 시도했는지를 나타냅니다.
- 낙관적인 유틸리티: 함수 𝑓(𝑢,𝑛)=𝑢+𝑘/√𝑛는 방문 횟수가 적을수록 더 큰 '보너스'를 추정치에 추가함으로써 에이전트가 덜 탐험한 상태와 행동을 시도하도록 유도합니다. 여기서 𝑘는 얼마나 많은 보너스를 주는지 조절하는 상수입니다.
- 정규 Q-업데이트: 이것은 Q-값을 업데이트하는 전통적인 방법으로, 에이전트가 현재 상태에서 행동을 취한 후의 보상과 다음 상태에서의 최대 Q-값을 결합하여 현재 Q-값을 업데이트합니다.
- 수정된 Q-업데이트: 이는 탐험 함수를 사용하여 Q-값을 업데이트하는 수정된 방식입니다. 이 방식은 에이전트가 덜 탐험한 상태와 행동을 더 많이 시도하도록 유도하여, 탐험과 착취 사이의 균형을 잡는 데 도움을 줍니다.
- 보너스의 역전파: 수정된 Q-업데이트는 알려지지 않은 상태로 이어지는 상태에 대한 Q-값을 업데이트할 때, 낙관적인 보너스를 포함시킵니다. 이는 알려지지 않은 상태를 탐험할 가능성을 높이기 위해 설계된 것입니다. 이렇게 함으로써, 에이전트는 알려지지 않은 상태를 발견했을 때 그 상태를 탐험하는 것에 대한 추가적인 '보상'을 받게 됩니다.
Optimality and Exploration
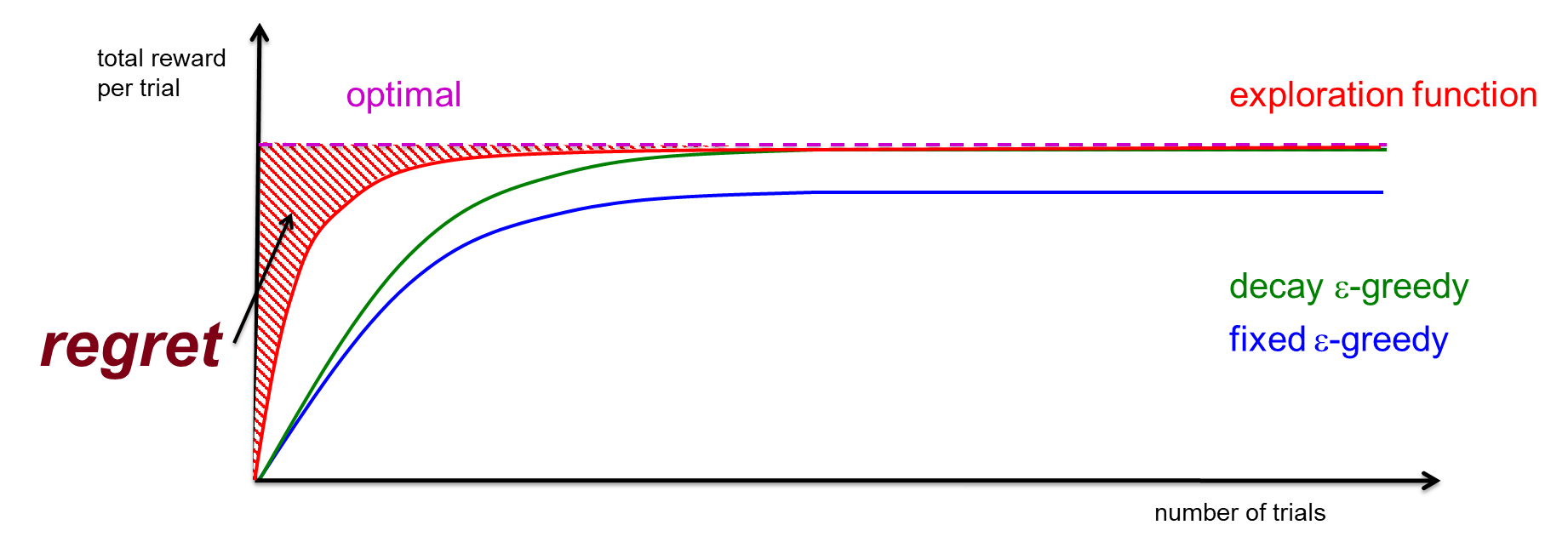
이 그래프는 강화 학습에서 최적성과 탐험 간의 관계를 나타내는 것으로 보입니다.
- 최적선(Optimal): 이 이상선은 시간이 지남에 따라 에이전트가 최적의 정책을 학습했을 때 기대할 수 있는 총 보상을 나타냅니다. 그래프에서 이 선은 가장 위에 위치하며, 이는 최고의 성과를 상징합니다.
- 탐험 함수(Exploration function): 이 선은 탐험 함수를 사용하여 탐험과 착취 간의 균형을 맞춘 상태에서 에이전트의 성과를 나타냅니다. 이 선은 최적선에 가장 가깝습니다. 탐험 함수는 적게 방문한 상태에 대해 더 높은 가치를 부여하여 탐험을 장려합니다.
- 감소하는 입실론 그리디(Decay ε-greedy): 이 방법은 입실론 값을 점차 줄여나가며, 처음에는 더 많은 탐험을 하다가 점점 착취를 하는 방향으로 바뀝니다. 그래프에서는 이 방법이 최적선보다는 낮지만, 고정된 입실론 그리디보다는 더 좋은 성과를 나타내고 있습니다.
- 고정된 입실론 그리디(Fixed ε-greedy): 이 전략은 입실론 값을 고정하고 시간이 지나도 변경하지 않습니다. 이 접근법은 탐험과 착취 사이에 일정한 비율을 유지하며, 그래프에서는 최적선과 탐험 함수보다 낮은 성과를 보여줍니다.
- 유감(Regret): 이 영역은 에이전트가 최적의 정책을 따랐을 때 얻을 수 있는 총 보상과 실제로 얻은 보상 사이의 차이를 나타냅니다. 이는 에이전트가 비효율적인 탐험을 하거나 착취에 너무 많이 의존함으로써 발생하는 손실입니다. 그래프에서 빨간색 줄무늬로 표시된 영역이 이를 나타내며, 탐험 함수를 사용한 접근법이 가장 적은 유감을 보여줍니다.
종합적으로, 이 그래프는 강화 학습에서 탐험과 착취 사이의 균형을 어떻게 잡는가에 따라 에이전트의 성과가 어떻게 달라지는지를 시각적으로 보여줍니다. 탐험 함수를 적절히 사용하는 것이 장기적으로 가장 효과적인 것으로 나타나며, 감소하는 입실론 그리디 방법도 나쁘지 않은 성과를 보여주는 반면, 고정된 입실론 그리디 방법은 더 많은 유감을 가져올 수 있습니다.
Regret
Approximate Q-Learning
Approximate Q-Learning은 강화 학습의 한 형태로, 실제 Q-Learning이 실용적이지 않을 때 사용됩니다. 이는 특히 상태 공간이나 행동 공간이 매우 크거나 무한할 때 적용됩니다.
Q-Learning의 기본
Q-Learning은 강화 학습의 한 종류로, 에이전트가 환경을 통해 행동하고 그 결과로부터 학습하는 방식입니다. 각 상태와 행동 쌍에 대한 Q-값(보상의 예상 가치)을 업데이트하면서 최적의 정책을 찾아갑니다. 이 이론적인 프레임워크는 상태와 행동 쌍 각각에 대해 별도의 Q-값을 저장하고 업데이트합니다.
Approximate Q-Learning의 필요성
실제 문제에서는 상태 공간이 너무 클 수 있어 모든 가능한 상태에 대해 Q-값을 저장하고 계산하는 것이 불가능할 수 있습니다. 예를 들어, 체스 게임에서 가능한 모든 보드 상태의 수는 상상을 초월합니다. 이러한 경우에는 모든 상태를 명시적으로 다루는 대신에 상태의 특징을 기반으로 Q-값을 추정하는 방법이 필요합니다.
Approximate Q-Learning의 원리
Approximate Q-Learning에서는 상태와 행동의 특징을 기반으로 한 함수(예: 선형 함수, 신경망 등)를 사용하여 Q-값을 근사합니다. 이 함수는 각 상태의 특징과 각 행동에 대한 가중치를 조합하여 Q-값을 추정합니다. 이 방법은 특징 선택과 가중치 학습에 의존합니다.
학습 과정
Approximate Q-Learning의 학습 과정은 다음과 같습니다:
- 특징 추출(Feature Extraction): 각 상태를 대표하는 특징을 추출합니다.
- 가중치 초기화(Weight Initialization): 각 특징에 대한 가중치를 초기화합니다.
- 경험 수집(Experience Collection): 에이전트가 환경과 상호작용하며 데이터(상태, 행동, 보상, 다음 상태)를 수집합니다.
- 가중치 업데이트(Weight Update): 수집된 경험을 바탕으로 가중치를 업데이트합니다. 이는 일반적으로 손실 함수를 최소화하는 방향으로 이루어집니다.
- 정책 개선(Policy Improvement): 업데이트된 가중치를 사용하여 보다 나은 정책을 수행합니다.
이러한 과정을 통해, Approximate Q-Learning은 상태 공간이 너무 크거나 복잡한 문제에서도 효과적으로 최적의 정책을 학습할 수 있습니다.
Generalizing Across States
- 기본 Q-러닝은 모든 Q-값들에 대한 테이블을 유지합니다.
- 현실적인 상황에서 우리는 모든 단일 상태에 대해 학습할 수 없습니다!
- 훈련 중에 모든 상태를 방문하는 것은 불가능합니다.
- 메모리에 Q-테이블을 모두 저장할 수 없습니다.
- 대신, 우리는 일반화하고 싶습니다:
- 경험으로부터 소수의 훈련 상태들에 대해 배웁니다.
- 그 경험을 새롭고 유사한 상황에 일반화합니다.
- 이를 위해 어떤 기계 학습 도구들을 적용할 수 있을까요?
상태 일반화는 강화 학습에서 상태 공간의 광대함과 복잡성에 대응하기 위해 필요한 전략입니다.
- 기본 Q-러닝의 한계: 기본 Q-러닝은 모든 가능한 상태와 행동의 조합에 대해 Q-값을 저장하는 Q-테이블을 사용합니다. 그러나 많은 실제 문제에서는 상태의 수가 너무 많아 모두 방문하거나 Q-테이블을 메모리에 저장하는 것이 불가능합니다.
- 일반화의 필요성: 이에 대한 해결책으로, 우리는 소수의 훈련 상태에서 배운 경험을 새롭고 유사한 상황에 적용하고자 합니다. 즉, 일부 상태에 대한 학습을 다른 상태에 일반화하여, 보다 넓은 상태 공간에 대한 결정을 내릴 수 있도록 합니다.
- 기계 학습 도구의 적용: 이 일반화 과정에는 기능 근사(function approximation)라는 기계 학습 도구가 사용될 수 있습니다. 이는 신경망이나 선형 회귀와 같은 모델을 사용하여 상태의 특징을 입력으로 받고 Q-값을 출력으로 내놓는 함수를 만드는 방식입니다. 이 함수의 매개변수나 가중치는 훈련 과정에서 학습됩니다.
이러한 기계 학습 도구들을 사용함으로써, 강화 학습 알고리즘은 한정된 경험을 바탕으로 더 넓은 범위의 상태에 대해 최적의 행동을 예측하고 결정할 수 있습니다. 이는 복잡한 환경에서 강화 학습을 적용할 때 필수적인 접근법입니다.
Example: Pacman

이미지에서는 클래식 아케이드 게임인 "팩맨(Pacman)"의 세 가지 다른 상태가 보입니다. 이 게임에서 플레이어는 팩맨을 조종하여 모든 점들을 먹으면서 유령들로부터 피해 다녀야 합니다. 게임의 목표는 모든 점을 먹고 다음 레벨로 넘어가는 것입니다.
강화 학습 관점에서 "팩맨" 게임은 다음과 같이 설명될 수 있습니다:
- 상태(State): 각 이미지는 팩맨의 위치, 유령의 위치, 남은 점들의 위치 등을 포함한 게임의 특정 순간을 나타냅니다. 강화 학습에서 이러한 모든 요소들은 환경의 '상태'를 구성합니다.
- 행동(Action): 팩맨은 상, 하, 좌, 우로 움직일 수 있는데, 이들은 가능한 '행동'입니다.
- 보상(Reward): 점을 먹거나 레벨을 완료할 때 팩맨은 보상을 받습니다. 반대로 유령에게 잡히면 패널티(음의 보상)를 받습니다.
- 정책(Policy): 팩맨의 이동 방향을 결정하는 전략입니다. 강화 학습에서는 최적의 정책을 배우는 것이 목표이며, 이는 최대한의 점수를 얻도록 팩맨을 움직이는 방법을 의미합니다.
강화 학습 알고리즘을 사용하여 "팩맨" 게임을 플레이하는 에이전트를 훈련시킬 수 있습니다. 이 과정에서 에이전트는 게임을 통해 얻은 경험을 바탕으로 최적의 행동을 학습하게 됩니다. Approximate Q-Learning이나 다른 일반화 기법을 사용하여, 에이전트는 게임의 모든 가능한 상태를 명시적으로 학습하지 않고도 유령을 피하고 점들을 효과적으로 수집하는 방법을 학습할 수 있습니다.
Demo Q-Learning Pacman – Tiny – Watch All
이 영상에선 팩맨 게임의 size가 굉장히 tiny한데 그래서 그런지 이길 때도 있고 질 때도 있고 결과가 시도를 할때마다 다르다
Demo Q-Learning Pacman – Tiny – Silent Train
여기선 직접 실행하지 않고 추상화? 등을 해서 평균 reward를 산출해낸다음에 최적의 행동을 반환하는 듯하다 . 그래도 시도를 할 때마다 이긴다. 그래서 silent train은 학습 과정에서 시각적인 효과 없이 백그라운드에서 에이전트 학습을 실행하면서 사용자에게 중간 과정을 보여주지 않고 최종 결과만 제시한다. 학습 과정은 사용자의 관점에서 볼 때 '조용한' 방식으로 진행됩니다. 즉, 훈련 과정에서 중간 출력이나 피드백 없이 내부적으로 이루어집니다. "Silent Train" 모드는 대개 학습 시간이 길거나, 많은 반복이 필요하거나, 사용자가 중간 과정보다는 최종 결과에 더 관심이 있을 때 사용됩니다.
Feature-Based Representations
특징 기반 표현(Feature-Based Representations)
- 상태를 특징 벡터를 사용하여 설명합니다.
- 특징들은 상태에서 실수로 매핑하는 함수들로, 상태의 중요한 속성들을 포착합니다(자주 0/1 값을 갖음).
- 예시 특징들:
- 가장 가까운 유령까지의 거리 𝑓_GST
- 가장 가까운 점(dot)까지의 거리
- 유령의 수
- 가장 가까운 점까지의 거리의 역수 𝑓_DOT
- 팩맨이 터널 안에 있는가? (0/1)
- …… 등등.
- 행동을 포함한 q-상태 (𝑠, 𝑎) 또한 특징들로 설명할 수 있습니다(예를 들어, 행동이 음식에 더 가까워지게 함).
특징 기반 표현은 강화 학습에서 각 상태를 간결하게 표현하는 방법으로, 상태의 중요한 정보를 요약하는 특징들로 구성됩니다. 이런 특징들은 학습 알고리즘이 상태를 더 잘 이해하고, 각 상태에 대한 최적의 행동을 결정하는 데 도움을 줍니다.
- 특징 벡터(Feature Vector): 각 상태를 설명하는 실수 값들의 벡터로, 해당 상태의 중요한 속성들을 수치적으로 나타냅니다. 예를 들어, 팩맨 게임에서 특징 벡터는 유령의 위치, 점의 위치, 터널의 존재 등과 같은 게임 상태의 핵심 요소들을 포함할 수 있습니다.
- 특징의 예시들: 각 특징은 특정 상태의 특성을 나타내는데, 예를 들어 가장 가까운 유령이나 점까지의 거리는 팩맨에게 중요한 정보를 제공합니다. 또한, 특정 상태에서의 유령의 수나 팩맨이 터널 안에 있는지 여부도 중요한 결정 요소가 될 수 있습니다.
- Q-상태의 특징 기반 표현: Q-러닝에서는 상태(s)뿐만 아니라 해당 상태에서 취할 수 있는 행동(a)도 함께 고려합니다. 특징들은 행동에 따른 결과, 예를 들어 음식에 더 가까워지는 행동을 할 때의 상태 변화를 설명하는 데 사용될 수 있습니다.
이러한 특징 기반 표현은 에이전트가 더 효율적으로 학습하고, 상태 공간이 크거나 복잡할 때 유용합니다. 에이전트는 이 특징들을 기반으로 상태 공간 내에서 일반화를 할 수 있고, 보지 못한 새로운 상태에 대해서도 효과적인 행동을 예측할 수 있습니다.
Linear Value Functions

선형 가치 함수는 강화 학습에서 (상태 가치 함수)와 (행동 가치 함수)를 추정하기 위해 사용되는 방법입니다. 여기서 각 상태 또는 상태-행동 쌍의 가치는 특징들의 선형 조합으로 표현됩니다. 이 특징들은 해당 상태 또는 상태-행동 쌍에서 중요한 정보를 캡쳐합니다.
- 가중치와 특징: 각 특징 또는 는 실수 값을 가지며, 이들은 가중치 와 곱해져 전체 가치를 계산하는 데 기여합니다. 이 가중치들은 학습 과정을 통해 조정됩니다.
- 근사치의 한계: 특징이 잘못 선택되거나 설계되면, 심지어 최선의 근사를 사용하더라도 결과가 좋지 않을 수 있습니다. 즉, 중요한 정보를 잘 반영하지 못하는 특징은 성능 저하를 일으킬 수 있습니다.
- 실제 적용: 그럼에도 불구하고, 선형 가치 함수는 실제로 매우 큰 상태 공간을 가진 문제들, 예를 들어 체스와 같은 게임에서도 유용하게 사용될 수 있습니다. 실제로 체스에서는 매우 많은 가능한 상태들을 약 30개 정도의 가중치로 요약하여 나름대로 합리적인 게임 플레이를 구현할 수 있습니다.
이러한 선형 가치 함수의 사용은 계산적으로 효율적이며, 강화 학습 에이전트가 복잡한 문제를 더 빨리 그리고 더 효과적으로 학습하도록 돕습니다.
Updating a Linear Value Function

선형 가치 함수를 사용하는 Q-러닝에서는 가중치를 업데이트하여 예측 오류를 줄이는 방식으로 작동합니다. 이 과정은 다음과 같이 이루어집니다:
- 오류 계산: 에이전트는 현재 상태와 행동 에서 받은 실제 보상 과, 다음 상태 에서 가능한 모든 행동 에 대한 최대 Q-값을 이용하여 예측 오류를 계산합니다.
- 가중치 업데이트: 이 오류를 바탕으로 각 특징에 대한 가중치 를 조정합니다. 가중치의 조정은 오류, 학습률 , 그리고 해당 가중치에 대한 특징 값 에 의존합니다.
- 질적 근거: '기분 좋은 놀람'은 보상이 기대보다 높을 때 발생하며, 이 경우 긍정적인 특징(예측에 도움이 된 특징)의 가중치를 증가시킵니다. 반대로 '기분 나쁜 놀람'은 보상이 기대보다 낮을 때 발생하며, 이 경우 긍정적인 특징의 가중치를 감소시킵니다.
이러한 과정을 통해, 에이전트는 경험을 통해 학습하면서, 점차적으로 보다 정확한 예측을 하는 모델을 개발하게 됩니다. 가중치 업데이트는 강화 학습에서 에이전트가 보다 높은 보상을 얻기 위한 최적의 행동 전략을 찾도록 돕습니다.
Example: Q-Pacman

이 이미지는 선형 가치 함수를 사용하는 Q-러닝 알고리즘을 적용한 팩맨 게임의 예시를 보여줍니다. 알고리즘은 팩맨의 상태와 행동을 기반으로 Q-값(기대되는 미래 보상)을 추정하고, 이를 통해 가중치를 업데이트합니다. 이 과정은 다음과 같습니다:

이 예시에서는 팩맨이 음식에 가까워질수록 Q-값을 증가시키고, 유령에 가까워질수록 Q-값을 감소시키는 방식으로 설계되어 있습니다. 그러나 팩맨이 유령에 잡히면서 큰 음의 보상을 받게 되어, 이 특징들의 가중치가 조정되어야 함을 보여줍니다. 이러한 업데이트는 향후 유령을 피해 더 안전한 경로를 선택하는 데 도움이 될 것입니다.
Demo Approximate Q-Learning – Pacman
이 팩맨 환경은 고스트가 두명이고 크기가 매우 크기 때문에 근사 q러닝을 시도한 것 같다. 팩맨의 처음 두 시도에서는 고스트한테 잡혀서 실패하지만 세번째 시도에서는 고스트에게 안걸리고 dot을 모두 모으는데 성공한다. 세번째는 좀 잘하나 싶더니 실패한다. 네 번째 시도에서는 세번째보다 잘하는거같다.
수렴(Convergence)
- 을 에 가장 근접한 선형 근사라고 합시다.
- 선형 함수 근사기를 사용하는 TD(Temporal Difference) 학습은 에 꽤 가까운 어떤 에 수렴합니다.
- 선형 함수 근사기를 사용하는 Q-러닝은 발산할 수 있습니다.
- 훨씬 더 복잡한 업데이트 규칙을 사용하면, 신경망과 같은 비선형 함수 근사기에 대해서도 강한 수렴 결과를 증명할 수 있습니다.
여기서 언급된 내용은 강화 학습에서의 함수 근사 방법과 그 수렴성에 관한 내용입니다.
- 과 : 은 어떤 환경에 대한 최적의 가치 함수를 나타내며, 은 이 최적의 가치 함수를 선형 함수로 근사한 것을 의미합니다.
- TD 학습의 수렴: TD 학습은 각 시간 단계에서 얻은 경험을 바탕으로 가치 함수의 추정치를 업데이트하는 방법입니다. 선형 함수 근사를 사용하는 TD 학습은 이론적으로 에 근접한 가치 함수 에 수렴하게 됩니다. 이는 각 상태의 가치가 실제로 관측된 보상과 예측된 미래 보상 사이의 차이(시간차 오류)에 기반하여 조정됨을 의미합니다.
- Q-러닝의 발산 문제: 반면, 선형 함수 근사기를 사용하는 Q-러닝은 항상 수렴하지 않을 수 있습니다. 이는 Q-러닝이 최적의 행동 가치 함수 를 추정하는 과정에서 발생할 수 있는 특정 조건 하에서는 가중치의 업데이트가 불안정해질 수 있기 때문입니다.
- 보다 복잡한 업데이트 규칙과 수렴성: 고급 강화 학습 알고리즘에서는 신경망과 같은 비선형 함수 근사기를 안정적으로 학습시킬 수 있는 복잡한 업데이트 규칙을 사용합니다. 이러한 규칙은 적절한 조건 하에서 가치 함수가 수렴하도록 보장하는 더 강력한 수렴 결과를 제공할 수 있습니다.
함수 근사기를 사용하는 강화 학습 알고리즘의 수렴성은 알고리즘의 안정성과 신뢰성을 보장하는 중요한 속성입니다. 그러므로, 실제 문제에 적용할 때는 수렴성을 잘 고려하여 알고리즘을 선택하고 설계해야 합니다.
Nonlinear Function Approximators

비선형 함수 근사자는 Q-러닝에서 상태와 행동에 대한 복잡한 관계를 모델링하기 위해 사용됩니다.
- 기울기 기반 업데이트(Gradient-Based Update): 이는 가중치 를 조정함으로써 함수를 최적화하는 방법입니다. 여기서, 는 학습률이고, 는 할인 인자입니다. 이 업데이트는 실제 받은 보상 과 추정된 미래 보상 사이의 차이(오류)를 바탕으로 수행됩니다.
- 신경망과 오류 역전파(Back-Propagation): 신경망에서는 오류 역전파를 사용하여 신경망의 가중치를 학습합니다. 이는 비선형 관계를 학습할 수 있는 강력한 메커니즘으로, 각 뉴런의 가중치를 입력과 출력 사이의 오류에 기반하여 조정합니다.
- 복잡한 신경망(Complex Neural Nets): 복잡한 신경망은 더욱 정교한 비선형 관계를 모델링할 수 있습니다. 이를 통해 에이전트는 선형 함수보다 더 정확하게 상태와 행동의 가치를 추정할 수 있습니다. 이는 특히 상태 공간이 매우 크거나 복잡할 때 유리합니다.
결과적으로, 신경망과 같은 비선형 함수 근사자를 사용하는 것은 강화 학습에서 더 복잡하고 현실적인 문제를 해결할 수 있는 능력을 제공합니다. 이는 에이전트가 보다 높은 수준의 추상화와 일반화를 통해 행동을 학습하도록 돕습니다.
DeepMind DQN
- 를 표현하기 위해 심층 학습 네트워크를 사용했습니다:
- 입력은 마지막 4개의 이미지(84x84 픽셀 값)와 점수를 포함합니다.
- 49개의 아타리 게임을 포함, 예를 들어 브레이크아웃, 스페이스 인베이더스, 시퀘스트, 엔듀로 등이 있습니다.
딥마인드의 DQN(Deep Q-Network)은 강화 학습과 딥러닝을 결합한 혁신적인 접근법입니다. 이 기술은 다음과 같은 특징을 가지고 있습니다:
- Q-함수의 딥러닝 표현: DQN은 심층 신경망을 사용하여 Q-함수를 근사합니다. 이 Q-함수는 주어진 상태에서 각 가능한 행동의 기대 보상을 예측하는 역할을 합니다.
- 입력 데이터: 신경망의 입력으로는 최근 4개의 연속된 게임 화면(이미지)과 현재 점수가 사용됩니다. 이는 시간에 따른 게임의 동적인 특성을 포착하기 위함입니다.
- 다양한 게임에서의 학습과 적용: 딥마인드의 DQN은 49개의 다른 아타리 게임에 대한 학습과 적용이 가능했습니다. 이러한 게임들은 다양한 종류의 게임 메커니즘을 가지고 있으며, DQN은 이러한 다양한 환경에서 일반화할 수 있는 능력을 보여주었습니다.
DQN의 성공은 컴퓨터 비전에서의 심층 학습 기술이 강화 학습 문제에 효과적으로 적용될 수 있음을 입증했습니다. 이는 또한 게임 환경에서의 시각적 인식과 결정을 통합하는 데 딥러닝이 중요한 역할을 할 수 있음을 시사합니다. DQN은 복잡한 게임 환경에서도 인간 수준의 플레이를 달성할 수 있는 첫 번째 알고리즘 중 하나로, 강화 학습 분야에 큰 영향을 미쳤습니다.
Summary
- 탐험 대 착취(Exploration vs. exploitation)
- 낯선 것에 대한 안내와 잠재력에 의한 탐험
- 적절하게 설계된 보너스는 유감을 최소화하는 경향이 있다
- 일반화는 RL을 실제 문제로 확장할 수 있게 해준다
- 또는 를 매개변수화된 함수로 표현
- 샘플 예측 오류를 줄이기 위해 매개변수를 조정
이 요약은 강화 학습의 두 가지 중요한 개념, 즉 탐험 대 착취와 일반화에 대해 설명합니다.
- 탐험 대 착취: 강화 학습에서는 에이전트가 이미 알고 있는 행동을 이용하는 착취와 새로운 정보를 얻기 위한 탐험 사이에서 균형을 찾아야 합니다. 에이전트가 낯선 상태나 높은 잠재 보상을 가진 상태를 탐험하도록 유도하는 것이 중요합니다. 이러한 탐험은 적절하게 설계된 보너스를 통해 유도되며, 장기적으로 최적의 행동 전략을 찾는 데 도움을 줍니다.
- 일반화: 일반화를 통해 강화 학습은 실제 크기의 문제에 적용될 수 있습니다. 상태 가치 함수 또는 행동 가치 함수 를 매개변수화된 함수로 표현하여, 보다 적은 수의 샘플로부터 학습할 수 있게 합니다. 이 함수들의 매개변수는 경험을 통해 얻은 데이터를 바탕으로 조정되며, 이를 통해 에이전트의 예측 오류를 줄이고 성능을 향상시킵니다.
이 요약은 강화 학습이 복잡한 문제를 효과적으로 해결할 수 있도록 설계된 전략과 기술을 강조합니다. 이러한 전략과 기술은 강화 학습이 현실 세계의 다양한 도전 과제를 해결하는 데 활용될 수 있음을 보여줍니다.